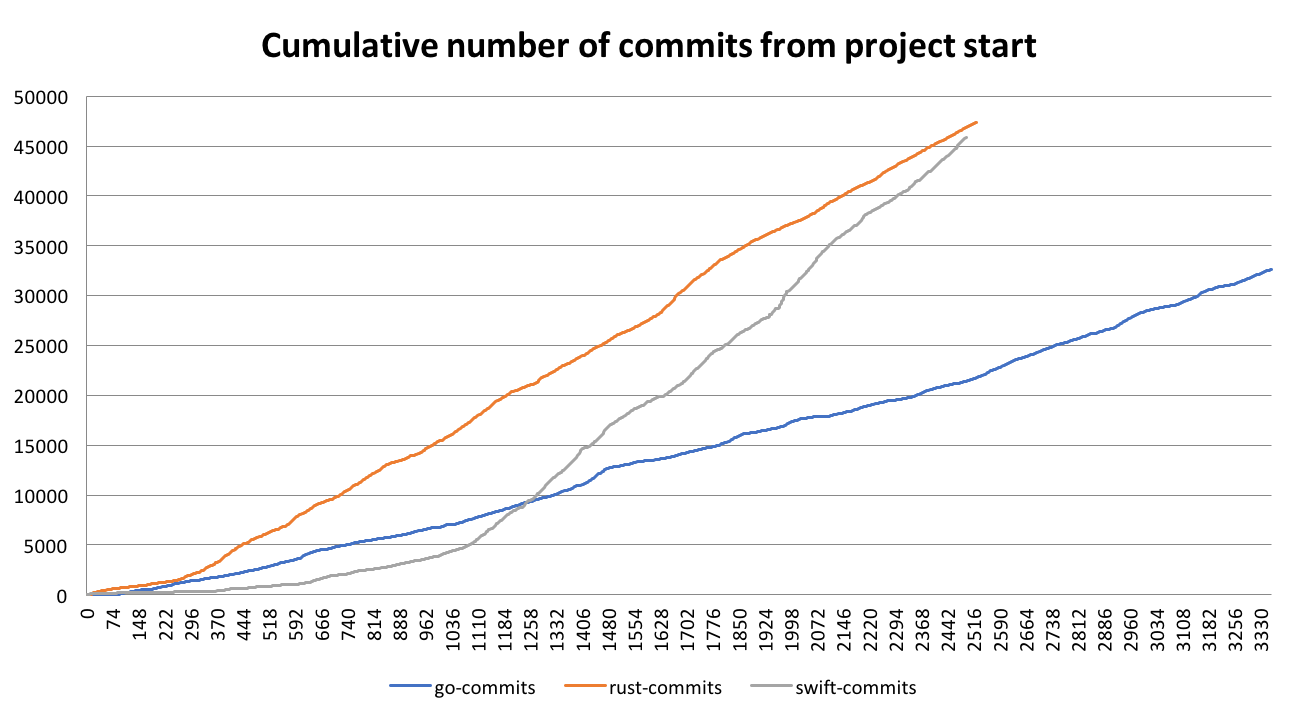
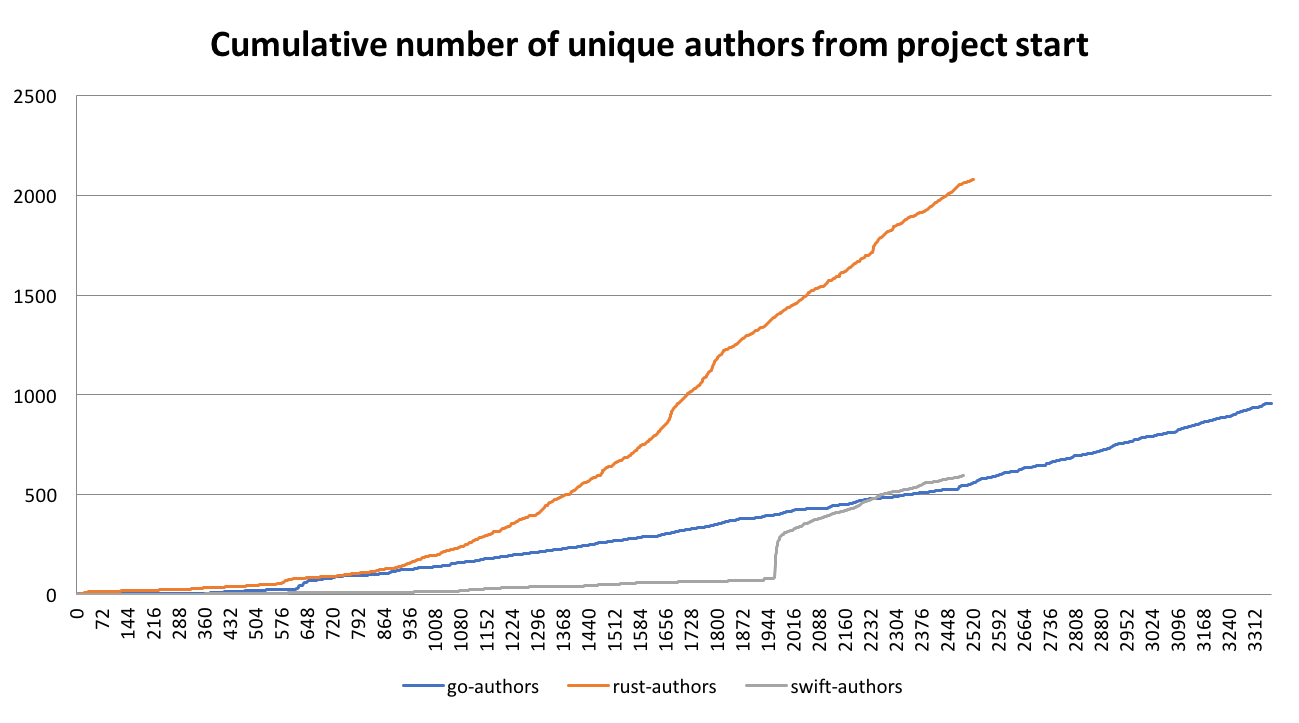
Like last year, the Rust community team asked community members to write blog posts "proposing goals and directions for 2019"; this is mine. Like withoutboats' post and Niko Matsakis' take, this post will focus on organizational issues. As such, the "ownership" from the title refers to a leadership principle, not the technical type system concept we all know and love.
Finance without fear
I believe the Rust project must figure out how accept donations for the benefit of the Rust language, compiler and ecosystem. Whether this involves a new legal entity or not, we should use the corporate money on the table where it could enable the community to move the ecosystem faster than otherwise possible.
Even if other communities have run into trouble with this, the focus of the Rust project on positive-sum outcomes and careful involvement with the community should make it possible to come up with proposals that are widely supported. Things like improving the state or scope of CI, having a procedural macro book written or even building custom tooling might all be good ideas.
So far, the Rust project has preferred existing tools over building our own. However, I think we run into the limitations of this strategy both in the example of CI and in the limitations of GitHub issues for some of the more involved discussions. This is a classic build vs buy discussion -- if we consider CI and RFC discussions to be a "core business" of the Rust project, then it might make sense to invest in improving these parts of the project's process.
(Is "tooling without terror" too terrible a pun?)
Foundation without fear
Setting up a legal entity and governance structure for the Rust project appears to be a controversial topic in the Rust community. Of course, it could be a home within an existing foundation: joining Thunderbird under the umbrella of the Mozilla Foundation, or another entity like the Software Freedom Conservancy. I would like the increased transparency and accountability that might come with a more explicit setup where it concerns how the leadership of the project evolves.
Since it keeps coming up, it would be good to have an RFC about the foundation idea; to have a thorough conversation on the benefits and downsides. If the latter end up outweighing the former, the RFC can serve as negative space documentation (per Graydon) for everyone thinking about it.
In a different vein, I think PEP 8016 is worth exploring as a carefully considered alternative we could crib ideas from. As an experiment, we could have part of the core team be elected by a (large cross-section of) the community.
Asynchronous alignment
I think the Rust project could benefit from an increased sense of the direction of the project. While the language design and library evolution processes "just" some adjustments to the increased scale at which we're operating, other parts of how the project executes are not so well-defined, or happen in synchronous meetings that are opaque to the community. I'm used to open source projects where decision making happens exclusively in asynchronous venues, and the current way Rust teams and working groups function is quite different -- with a notable exception for the way the compiler team documents their work.
The yearly roadmap building effort is one great way of doing this, but the yearly cycle makes it a very coarse-grained check-in. One suggestion I've been thinking about is to have a community event (maybe with video?) every release cycle or two where a group of core team members answers crowd-sourced questions from the community (along the lines of an AMA or Google's TGIF event).
This could also help cut down on the "Why don't you just" and "Be Heard" sentiments that I've seen core project team members lament over the past year. I think those sentiments come from a feeling of powerlessness and being underinformed. In my mind, more deliberate and continuous communication about the state of the project could go a long way towards improving on this.
Careful conduct
Although I wholly support the code of conduct and appreciate many aspects of the way we interact online, there's some things that I think could be improved. While I've seen people expressing their personal frustration with a project decision get quickly moderated, I've also seen users who keep posting vague forum threads or exert significant stop energy on others' proposals. I wish we could be more openly critical of decisions (not people) while at the same time more strict towards net-negative participants.
On a more subtle note, I've felt that core project team members cast the community as an angry mob at times. Although I realize it is a big job, I think it's fair to ask project leaders to bring more empathy to the table in these cases -- to me, that is an important part of leadership. If a significant part of the community is up in arms about something, there likely is a kernel of truth to their argument, and the leadership should respond to the sentiment to prevent it from festering.
Update: interesting discussion on these topics on Reddit.
Taking the long view
To my taste, too much focus in 2018 was spent on releasing the edition. We could have spent more time addressing technical and organizational debt and released the edition 3 or 6 months later to little consequence. The Rust release process has been carefully engineered to optimize for cautious movement towards long-term goals -- and the edition process, in setting a fixed scope and an arbitrary hard deadline, subverted a number of these goals. This caused issues around the release of the website as well as problems with tools when 1.31 was released.
On the one hand, the cautious, deliberate approach to language design and compiler development have served us well, and will likely continue to do so. However, we should not forget that this process functions well in part due to an imposed feedback cycle that gives enough time and space for people to experiment before casting the new feature in (stable) stone per Hyrum's law. In a similar vein, we cannot expect to get our organizational changes right on the first try, and so we should not be afraid to experiment and iterate with the way the community works on the Rust project, rather than taking a long time to get it just right. This is especially true because the experiment period allows a wider community to participate and interact with the proposed change, thus reinforcing community alignment and improving feedback.
In this sense, we might learn from Jeff Bezos when he talks about a bias to action, saying that we should not spend too much time discussing decisions that are easy to change after the fact. For Rust, too, we want to remain at Day 1 for as long as we can -- let's remember the "without stagnation" part.
Contemplating Cargo
On a somewhat more technical note, I hope for more attention given to Cargo. While Cargo is a great tool in many ways, it also suffers from a number of usability cliffs where the behavior is hard to predict or understand. When I tried to contribute, I found that there's also a decent amount of technical debt, and my attempts to improve this through refactoring were met with such reluctance that I stopped contributing. From recent reports, it seems I'm not the only one.
Since Cargo is so central to the Rust experience, I think we should not undervalue it; as one example, the interactions between Cargo and rustc also influence the perception of those compile times people keep talking about. I was very happy to see the leadership changes and increase of the team's size, and I hope those changes will lead to further Cargo improvements this year.
Unused inventory, redux
Last year, I wrote at some length about the concept of unused inventory. This is still very much on my mind, and I was happy to see Niko talk about it in very similar terms. I hope we can improve things here.
Closing thoughts
I'm still as bullish on the Rust language as ever. Non-lexical lifetimes and the module system changes have made an already great language even better, async/await is going to be great. What I most want from Rust, though, is that more of the software in my life can enjoy its reliability and efficiency (in performance vs footprint), and for that we need adoption and sustainability. While the technical side of the project is working well, I've been concerned about the functioning of the project's governance and processes. A number of Rust 2019 posts have addressed similar concerns, which makes me hopeful for 2019.